Introduccion a Kafka
Hoy hemos venido a jugar con Kafka o mejor dicho Apache Kafka, ya que se trata de un proyecto bajo el paraguas de Apache Foundation. No todo el mundo es consciente de la aportacion de esta institucion, con sus cientos de proyectos. Pues vamos allá, Apache Kafka, es un sistema de mensajes basado en un Patron Publisher/Suscriber, distribuido, particionado, resiliente y replicado. Veremos sus caracteriticas principales y despues como de costumbre montaremos una pequeña arquitectura con Kafka en un entorno local, con varios productors y consumidores. Para hacerlo lo más real posible plantearemos un entorno lo mas heterogeneo posible, con piezas en Python y en PHP (Si, PHP tambien sabe jugar con Kafka)
En un principio, nuestra empresa era pequeña, con unos poco servicios nos apañabamos. la monitorización se hacia de aquella manera o simplemente no habia, habia varios servidores que tenian varios roles y todo iba la mar de bien. En un momento dado la empresa empieza a crecer, y se le añade esto y aquello. Los sistemas van madurando, de tal manera que lo que en un principio era un sistema facil de desarrollar y mantener se convierte en una tarea imposible. Tenemos un sistema muy heterogeneo, con partes en Java, otras partes en ASP y las partes mas actualizadas en PHP o Python, cualquier cambio supone un desafio, posiblemente parada de servicio, lo que vemos aqui:
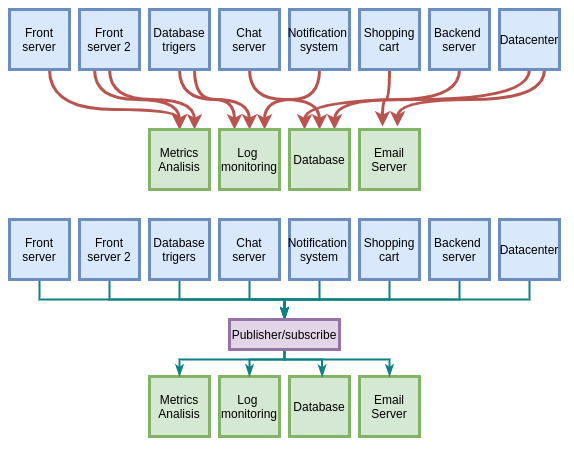
Para poder poner un poco de orden en todo ese caos de streaming de datos se introdujo un sistema basado en un patron publisher/suscriptor, y eso mejoró sustancialmente el escenario. Cada sistema requerió de su propia API para poder hablar con el sistema de publicación, fue un currazo, pero mejoro mucho. Bien, pues lo que nos trae Kafka es dar uniformidad al sistema ofreciendo la misma interfaz a todos los sistemas.
Antes de comentar cada unas de esas palabras que definen a Kafka vamos a detenernos en eso del Patrón de diseño Publicador/Suscriptor. En un entorno donde existen diversas clases cooperantes que intercambian informacion corremos el riesgo de provocar un fuerte acoplamiento, que hará a la larga un mantenimiento tedioso que propaga cambios forzados en todo el sistema. No tienen que ser necesariamente clases, pueden ser entidades de un ecosistema que se acoplan y dependen entre ellas. Por ejemplo un notificador de transacciones economicas, imaginemos que tenemos una plataforma de ventas. Cada venta produce una llamada al sistema de logs de la empresa, otra llamada a marketing para registrar sus métricas y otra al sistema de correo para notificar al cliente que la venta se ha completado con éxito. Las piezas no se conocen entre ellas pero trabajan como si fueran una sola. En definitiva: buscamos alta cohesión, y bajo acoplamiento. El sistema hace una unica cosa, y cada pieza es lo más independiente posible, pero claro nuestras cuatro entidades siguen necesitando pasar informacion entre ellas.
Los protagonistas de este patron, tambien conicido como Observador, son el Sujeto y observador. El sujeto puede tener n observadores, cada vez que el sujeto cambia de estado notifica a sus observadores. En respuesta cada observador consultará al objeto para sincronizarsu estado con el estado de éste. El sujeto es quien publica las notificaciones. Un numero indeterminado de observadores pueden suscribirse para recibir dichas notificaciones. De esta manera evitamos el acoplamiento Sujeto - Observador. Modificar la notificacion, que es agnostica de los consumidores, haya los que haya no tiene ninguna repercusion y nos permite reusarlos de forma independiente. Vale. 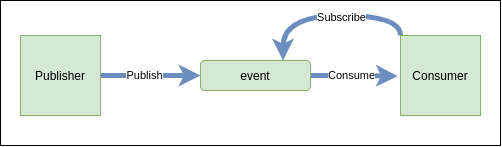
Kafka fue desarrollado inicialmente por Linkedin, pero pronto fue adoptada por otros grandes servicios, Netflix, Airbnb, Pinterest, Coursera,etc. La descripción aparentemente sencilla oculta un desarrollo bastante complejo, y es que Kafka es la suma de una serie de herramientas que permiten su magia. Empecemos, qué significa distribuido. Distribuido es que Kafka como tal no funciona en una maquina sino en un cluster de servidores trabajando para el mismo propósito. Este cápitulo está resuelto gracias a la ayuda de Zookeper. Zookeper, deacuerdo a su definicion oficial, es un servicio centralizado para mantener la información de configuración, nombrado, proporcionar sincronización distribuida y proporcionar servicios de grupo. Es decir, provee de lo necesario para poder tener una aplicacion distribuida en una serie de nodos que trabajan concurrentemente para una misma funcion.
Kafka trabaja en un sistema particionado de tal manerera que grupos de maquinas o brokers se encargan de gestionar diferentes grupos de mensajes entre productor y consumidor. El hecho de que haya una entidad supervisando la salud de las máquinas nos permite ver su carga, nos garantiza que en un momento dado si una de las máquinas cae, alguno de los esclavos retome el trabajo para poder continuar sin tener perdida de mensajes. Esto es gracias a la replicación con la que se establece el particionado. Cada uno de los topics no se puede crear con un replicacado superior al número de brokers. Evidentemente si pretendo tener un replicado para mi topic de 3 pero solo tengo dos brokers, no dispongo de máquina para ello. Lo normal es tener un replicado de 2 o 3. Estos conceptos ahora son un poco abstractos pero luego conectaremos todo.
Topics, Particiones y offsets. Un topic es un stream de datos, desde el productor al(os) consumidor(es). Podemos tener muchos topics, y cada uno se va a identificar por su nombre. Los topics están divididos en particiones que se configuraran en el momento de la creación del mismo. Cada particion esta ordenada por id y cada mensaje dentro de la particion tiene un id incremental. Los ids dentro de cada una de las particiones podran estar repetidos. EL offset 6 de las particiones 0 y 1 no se puede sabe cual de los dos mensajes es previo, sin mirar dentro del mensaje. El offset dentro de una particion, afecta unicamente a ésta. El offset de la particion 0 no es el mismo que la particion 1. Por defecto la info esta guardada en Kafka por un tiempo, por defecto una semana. pero los offsets no vuelven a 0, siempre van incrementandose. Y otro detalle es que la informacion es inmutable, no se puede alterar. Los datos se van distribuyendo entre las particiones aleatoriamente a no ser que se le pase una key, en ese caso los mensajes siempre van a la misma particion. La key es un String o numero, en caso de ser NULL se ira distribuyendo entre las particiones siguiendo un orden, Round Robin.
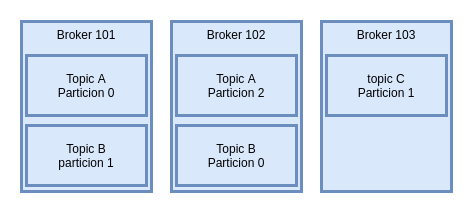
Clusters y Brokers. Los topics y las particiones siempre estan en un broker y un cluster está compuesto de brokers. Es decir un broker es un servidor. Cada broker tiene un id arbitrario que lo identifica. Cada broker tiene ciertos tipos de particiones de un topic aunque no necesariamente todos. Solo un broker puede ser lider para una particion y solo este puede servir datos para una particion, los otros brokers solo pueden sincronizar. Así, tenemos que cada particion tiene un leader y varios ISR, In-Sync-Replica. Entonces, cada Productor escribe mensajes en un topic, que esta compuesto de particiones y sabrá en todo momento, en que broker escribir. En caso de fallo de un broker, automaticamente se recuperará y sabrá donde tiene que escribir manteniendo la integridad del servicio. Zookeper se encargará de mantener la lista de todos los brokers, y ayudará a la eleccion de la particion leader. Zookeper se encargara de enviar notificaciones en caso de cambios, nuevo topic, muerte de un broker, nacimiento o borrado de un topic. El descubrimiento de los brokers es un proceso por el cual los clientes averiguan la estructura del cluster, preguntando a cualquiera de los brokers. Cada broker conserva unos metadatos con la informacion de cada broker del cluster, IP, particiones, topics, etc. Y hasta aqui una introduccion de los conceptos mas importantes del mundillo de Kafka, vamos ahora a empezar a hac algo mas practico, como de costumbre de la mano de Docker. Docker-compose nos creará dos contenedores, uno para zookeper, que ya he comentado que es esencial para Kafka y el propio Kafka. Como en otras ocasiones os he dejado un repo con el dockerfile listo para descargar.
En https://github.com/danielgimeno/kafka teneis toda la info, pegad el siguiente comando y lo tendreís listo:
git clone git@github.com:danielgimeno/kafka.gitPerfecto pues si lo descargamos veremos algo como:
version: "3"
services:
zookeeper:
image: zookeeper
restart: always
container_name: zookeeper
hostname: zookeeper
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
kafka:
image: wurstmeister/kafka
container_name: kafka
ports:
- 9092:9092
environment:
KAFKA_ADVERTISED_HOST_NAME: XXX.YYY.ZZZ.WWW
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
kafka_manager:
image: hlebalbau/kafka-manager:stable
container_name: kakfa-manager
restart: always
ports:
- "9000:9000"
environment:
ZK_HOSTS: "zookeeper:2181"
APPLICATION_SECRET: "random-secret"
command: -Dpidfile.path=/dev/null
Como vereis hay tres contenedores, uno para zookeper, otro para Kafka y finalmente, otro para Kafka Manager que nos permitirá ver algo de información de nuestro kafka y configurar algunas cosas, brokers, particiones, topics, etc. Bien, actualizamos la ip de nuestro host y lanzamos el compose.
daniel@dockerito:~/proyectos_dockerito/kafka-installation$ docker-compose -f docker-compose.yml up
Starting zookeeper ... done
Starting kafka ... done
Starting kakfa-manager ... done
Attaching to zookeeper, kafka, kakfa-manager
zookeeper | ZooKeeper JMX enabled by default
zookeeper | Using config: /conf/zoo.cfg
kafka | Excluding KAFKA_HOME from broker config
kafka | [Configuring] 'advertised.host.name' in '/opt/kafka/config/server.properties'
kafka | [Configuring] 'port' in '/opt/kafka/config/server.properties'
kafka | [Configuring] 'broker.id' in '/opt/kafka/config/server.properties'
kafka | Excluding KAFKA_VERSION from broker config
kafka | [Configuring] 'zookeeper.connect' in '/opt/kafka/config/server.properties'
kafka | [Configuring] 'log.dirs' in '/opt/kafka/config/server.properties'
kafka-manageer
org.apache.zookeeper.metrics.impl.DefaultMetricsProvider@11fc564b
zookeeper | 2021-01-04 17:06:57,446 [myid:1] - INFO [main:FileTxnSnapLog@124] - zookeeper.snapshot.trust.empty : false
zookeeper | 2021-01-04 17:06:57,648 [myid:1] - INFO [main:ZookeeperBanner@42] -
zookeeper | 2021-01-04 17:06:57,650 [myid:1] - INFO [main:ZookeeperBanner@42] - ______ _
zookeeper | 2021-01-04 17:06:57,654 [myid:1] - INFO [main:ZookeeperBanner@42] - |___ / | |
zookeeper | 2021-01-04 17:06:57,654 [myid:1] - INFO [main:ZookeeperBanner@42] - / / ___ ___ | | __ ___ ___ _ __ ___ _ __
zookeeper | 2021-01-04 17:06:57,654 [myid:1] - INFO [main:ZookeeperBanner@42] - / / / _ \ / _ \ | |/ / / _ \ / _ \ | '_ \ / _ \ | '__|
zookeeper | 2021-01-04 17:06:57,654 [myid:1] - INFO [main:ZookeeperBanner@42] - / /__ | (_) | | (_) | | < | __/ | __/ | |_) | | __/ | |
zookeeper | 2021-01-04 17:06:57,654 [myid:1] - INFO [main:ZookeeperBanner@42] - /_____| \___/ \___/ |_|\_\ \___| \___| | .__/ \___| |_|
zookeeper | 2021-01-04 17:06:57,654 [myid:1] - INFO [main:ZookeeperBanner@42] - | |
zookeeper | 2021-01-04 17:06:57,654 [myid:1] - INFO [main:ZookeeperBanner@42] - |_|
zookeeper | 2021-01-04 17:06:57,654 [myid:1] - INFO [main:ZookeeperBanner@42] -
Si queremos que no nos adjunte las trazas podemos ejecutar el compose -d o detached, es decir en background: docker-compose up -d. Correcto, con esto tendríamos el kafka funcionando. Ahora el siguiente paso es tener un topic antes de poner a funcionar los productores y consumidores.
daniel@dockerito:~/proyectos_dockerito/kafka-installation$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8c4e7beb33ca wurstmeister/kafka "start-kafka.sh" 2 minutes ago Up 2 minutes 0.0.0.0:9092->9092/tcp kafka
4b152b6f32bc hlebalbau/kafka-manager:stable "/kafka-manager/bin/…" 6 weeks ago Up 2 minutes 0.0.0.0:9000->9000/tcp kakfa-manager
38809ec2d6fa zookeeper "/docker-entrypoint.…" 6 weeks ago Up 2 minutes 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp zookeeper
Para ello lo que vamos a hacer es entrar: en el contenedor de Kafka y ejecutar un par de comandos. Hemos visto que el id del contenedor de Kafka es el 8c4e7beb33ca. Perfecto pues vamos entrar
docker exec -it 8c4e7beb33ca bash
nos cambia el prompt y ya vemos que estamos dentro asiq ue vamos a /opt/kafka_2.13-2.6.0/bin y ahi podemos ver una seie de comandos que nos permitiran interaccionar con Kafka:
connect-distributed.sh kafka-consumer-perf-test.sh kafka-reassign-partitions.sh trogdor.sh
connect-mirror-maker.sh kafka-delegation-tokens.sh kafka-replica-verification.sh windows
connect-standalone.sh kafka-delete-records.sh kafka-run-class.sh zookeeper-security-migration.sh
kafka-acls.sh kafka-dump-log.sh kafka-server-start.sh zookeeper-server-start.sh
kafka-broker-api-versions.sh kafka-leader-election.sh kafka-server-stop.sh zookeeper-server-stop.sh
kafka-configs.sh kafka-log-dirs.sh kafka-streams-application-reset.sh zookeeper-shell.sh
kafka-console-consumer.sh kafka-mirror-maker.sh kafka-topics.sh
kafka-console-producer.sh kafka-preferred-replica-election.sh kafka-verifiable-consumer.sh
kafka-consumer-groups.sh kafka-producer-perf-test.sh kafka-verifiable-producer.sh
Elegiremos el comando kafka-topic.sh para crear un nuevo topic:
bash-4.4# ./bin/kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1 --topic test
como comenté anteriormente el replication factor nos dira como se replica el topic dentro del cluster. Como solo tenemos 1 broker, solo hay posibilidad de que exista 1. Ahora podemos listar los topics del sistema haciendo un --list:
bash-4.4# ./bin/kafka-topics.sh --list --zookeeper zookeeper:2181
registered_user
test
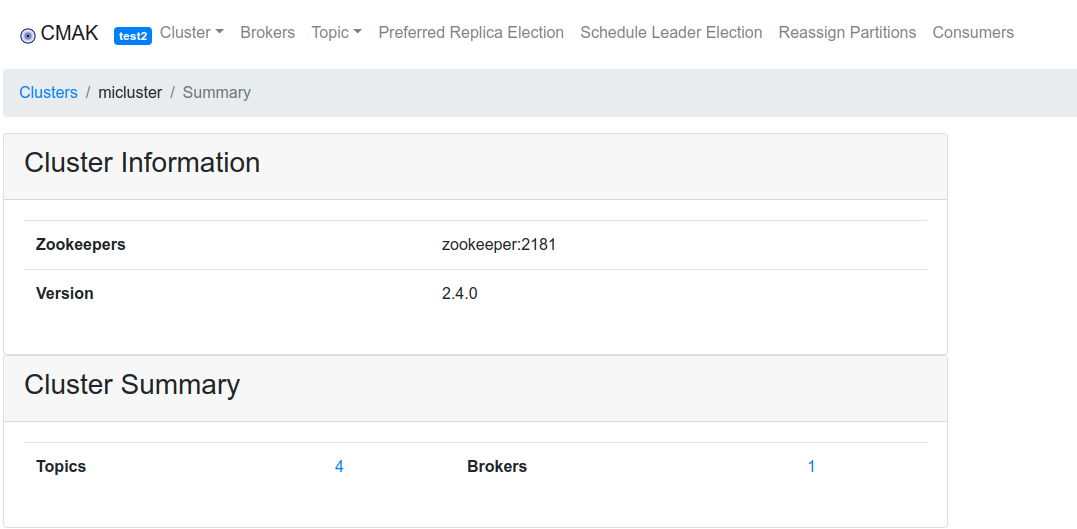
Esto está muy bien pero resulta algo pesado configurar Kafka por scripts, así que lo que vamos a hacer es usar el manager que hemos instalado anteriormente. Si nos fijamos en el compose veremos que iba a responder en el puerto 9000, pues nos vamos al ip del host con el puerto 9000. Ahí veremos un interfaz web muy amigable:
Y ahora viene lo interesante, vamos a crear un productor en python que genera registros y los envia al topic de fakeusers, y un consumidor en PHP que consume de dicho topic. En la maquina del productor vamos a instalar un par de librerias de python, Fake y Kafka. Fake es una libreria que genera registros de gente random, y si ejecutamos data.py despues de hacer un pip3 install fake sale:
daniel@dockerito:~/proyectos_dockerito/kafka-installation/producer$ cat data.py
from faker import Faker
fake = Faker()
def get_registered_user():
return {
"name": fake.name(),
"address": fake.address(),
"created_at": fake.year()
}
print (get_registered_user())
daniel@dockerito:~/proyectos_dockerito/kafka-installation/producer$ python3 data.py
{'name': 'Steven Brown', 'address': '02850 Pratt Squares Apt. 274\nRyanbury, NC 12333', 'created_at': '1978'}
daniel@dockerito:~/proyectos_dockerito/kafka-installation/producer$ python3 data.py
{'name': 'Mr. Victor Miranda', 'address': '75373 Cynthia Port\nEast Melissa, CA 82793', 'created_at': '2009'}
daniel@dockerito:~/proyectos_dockerito/kafka-installation/producer$
Esas lineas tan molonas serán nuestros mensajes para el topic fakeusers.
daniel@dockerito:~/proyectos_dockerito/kafka-installation/producer$ cat producer.py
from kafka import KafkaProducer
import json
from data import get_registered_user
import time
def json_serializer(data):
return json.dumps(data).encode("utf-8")
producer = KafkaProducer(bootstrap_servers=['192.168.1.124:9092'],
value_serializer=json_serializer)
if __name__ == "__main__":
while 1 == 1:
registered_user = get_registered_user()
print(registered_user)
producer.send("fakeusers", registered_user)
time.sleep(4)
Entonces nuestro productor llama a producer.send con el nombre del topic y el contenido del registro y esto lo hara cada 4 segundos. Por otro lado el consumidor en PHP, igual que en python requerirá la instalación de la librería librdkafka. Si hacemos un phpinfo, deberiamos poder ver:
daniel@med030 ~/proyectos/php-rdkafka-consumer php info.php | grep kafka
/etc/php/7.2/cli/conf.d/20-rdkafka.ini,
rdkafka
rdkafka support => enabled
librdkafka version (runtime) => 0.11.3
librdkafka version (build) => 0.11.3.255
Perfecto! eso es que esta instalado. Pues ya solo nos resta ponerlo todo a correr, el productor a producir y el consumidor a consumir. Aqui el productor:
✘ daniel@med030 ~/proyectos/kafkaprod python3 producer.py
{'name': 'Shelia Morgan', 'address': '3169 Jenna Lights\nNorth Carla, OR 24599', 'created_at': '2015'}
{'name': 'Sara Hart', 'address': 'PSC 6266, Box 0588\nAPO AE 06432', 'created_at': '2005'}
{'name': 'Joseph Best', 'address': '433 Ortiz Falls\nMontoyafurt, DC 33980', 'created_at': '1997'}
{'name': 'Corey Daugherty', 'address': '27170 Knight Court Suite 884\nMichaelfurt, SC 26691', 'created_at': '1989'}
Aqui el consumidor:
daniel@med030 ~/proyectos/php-rdkafka-consumer php consumer.php
object(RdKafka\Message)#5 (8) {
["err"]=>
int(0)
["topic_name"]=>
string(9) "fakeusers"
["timestamp"]=>
int(1609802723400)
["partition"]=>
int(0)
["payload"]=>
string(102) "{"name": "Shelia Morgan", "address": "3169 Jenna Lights\nNorth Carla, OR 24599", "created_at": "2015"}"
["len"]=>
int(102)
["key"]=>
NULL
["offset"]=>
int(0)
}
object(RdKafka\Message)#6 (8) {
["err"]=>
int(0)
["topic_name"]=>
string(9) "fakeusers"
["timestamp"]=>
int(1609802727402)
["partition"]=>
int(0)
["payload"]=>
string(90) "{"name": "Sara Hart", "address": "PSC 6266, Box 0588\nAPO AE 06432", "created_at": "2005"}"
["len"]=>
int(90)
["key"]=>
NULL
["offset"]=>
int(1)
}
object(RdKafka\Message)#5 (8) {
["err"]=>
int(0)
["topic_name"]=>
string(9) "fakeusers"
["timestamp"]=>
int(1609802731409)
["partition"]=>
int(0)
["payload"]=>
string(98) "{"name": "Joseph Best", "address": "433 Ortiz Falls\nMontoyafurt, DC 33980", "created_at": "1997"}"
["len"]=>
int(98)
["key"]=>
NULL
["offset"]=>
int(2)
}
No more messages; will wait for more
object(RdKafka\Message)#5 (8) {
["err"]=>
int(0)
["topic_name"]=>
string(9) "fakeusers"
["timestamp"]=>
int(1609802735413)
["partition"]=>
int(0)
["payload"]=>
string(115) "{"name": "Corey Daugherty", "address": "27170 Knight Court Suite 884\nMichaelfurt, SC 26691", "created_at": "1989"}"
["len"]=>
int(115)
["key"]=>
NULL
["offset"]=>
int(3)
}
Este flujo de llegada es cada 4 segundos, pero en pruebas en un entorno local, se podrian legar facil a miles por segundo. Espero que os haya sido de utildidad, al menos para poder ubicar las principales piezas.